Prometheus是一个开源的监控系统和时间序列数据库。为了确保监控数据的持久化存储,Prometheus提供了多种解决方案。其中,Mimir是一个分布式时间序列数据库,专门用于存储和查询大规模的时间序列数据。通过将Prometheus与Mimir集成,可以实现监控数据的持久化存储和高效查询。
持久化方案
目前市面上Promethus的持久化方案有以下几种:
- Thanos:Thanos是为了解决Prometheus的长期存储和高可用性问题而设计的。它提供了全局的查询视图,可以将数据存储到对象存储中,比如S3,这样数据可以长期保留。
- Cortex:Cortex是基于Prometheus的横向扩展方案,主要用于多租户的监控场景。它支持将Prometheus的数据远程写入到Cortex,然后进行分布式存储和处理。
- Mimir:Mimir是Cortex的升级版由Grafana Labs开发,可以实现Prometheus数据的持久化存储和高效查询。
三种方案对比
| 工具名称 | 优点 | 缺点 |
|---|---|---|
| Thanos | 兼容 Prometheus 生态,无缝集成支持长期存储(对象存储,成本低)提供全局聚合查询视图支持数据降采样与压缩 | 查询性能依赖对象存储性能组件较多,部署复杂度中等缺乏原生多租户支持仅适用于 Prometheus 数据源 |
| Cortex | 水平扩展能力强,支持海量指标写入原生多租户隔离,适合多团队场景完全兼容 PromQL数据分片存储,灵活性高 | 架构复杂,运维成本高查询性能中等,响应延迟较高存储效率低于 Mimir需手动调优分布式组件 |
| Mimir | 超高性能(查询速度比 Cortex 快 10 倍+)存储效率高(列式压缩,成本更低)自动化运维,部署复杂度低原生多租户与细粒度管控 | 新项目成熟度相对较低超大规模场景资源消耗较高对中小规模场景可能“杀鸡用牛刀”依赖 Grafana Labs 商业支持 |
为什么选择Mimir作为Prometheus的替代方案?
- 超高性能: Mimir 提供了比Cortex快十倍以上的查询速度,这意味着更快的数据检索和实时性更强的监控反馈。对于需要快速响应的应用场景,这是一个显著的优势。
- 高效的存储管理: Mimir 使用列式压缩技术来存储数据,这不仅降低了存储成本,还提高了读取效率。相比传统的行式存储,列存方式对分析型查询更为友好,尤其适合处理大规模时间序列数据。
- 简化运维: 相较于其他解决方案如Thanos或Cortex, Mimir提供了更简化的部署流程以及更低的运维复杂度。自动化运维特性使得维护更加容易,减少了人工干预的需求。
- 原生多租户支持与细粒度控制: Mimir 内置了对多租户的支持,并允许进行细粒度的权限管理和资源隔离,这对于那些在同一平台上有多个团队或者项目的组织来说非常重要。它能够确保不同用户组之间的安全性和独立性。
- 高可用性和可扩展性: Mimir 设计之初就考虑到了高可用性和水平扩展的能力,可以轻松应对日益增长的数据量和并发访问压力。其分布式架构保证了即使部分节点故障也不会影响整体服务稳定性。
- 商业支持和服务: 由Grafana Labs开发并维护,官方提供的技术支持和持续更新为使用Mimir的企业级用户提供了一定程度上的保障。此外,还有活跃社区的支持帮助解决遇到的问题。
Mimir 架构图
Mimir由一下几个核心组件组成,他们协同工作,共同实现大规模日志数据的收集、存储和查询。
下图是Mimir的架构图:
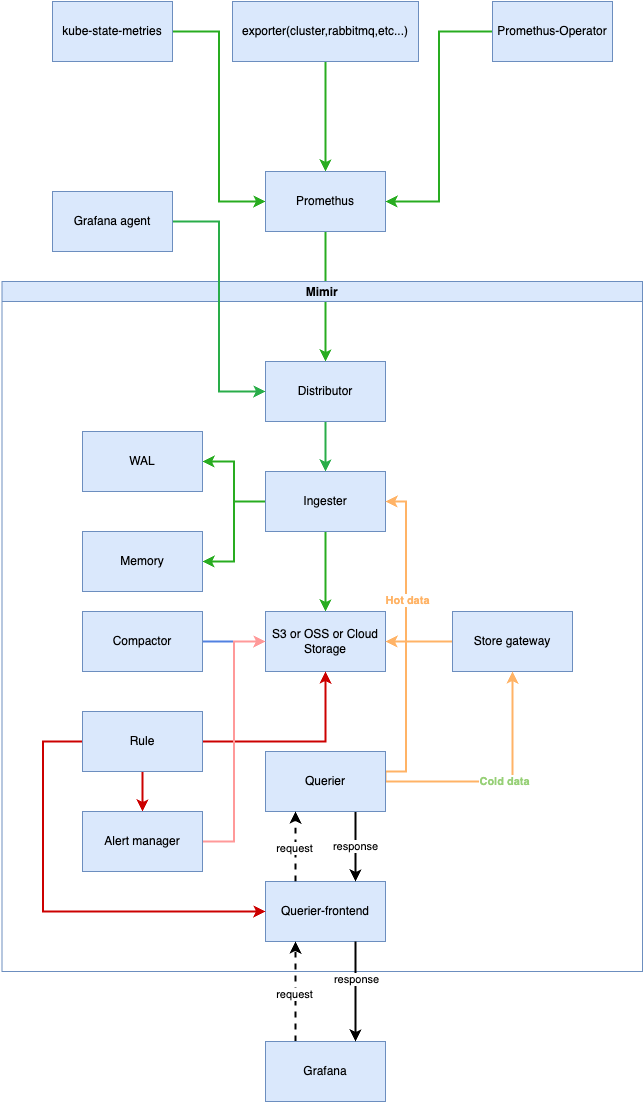
我们通过以下两个方面来阐述Mimir的架构设计:
数据存储流程
- Promethus通过将数据发送给Distributor(分发器)组件
- Ingester(摄取器)接收来自 Distributor(分发器)的传入样本。接收到的样本既保存在内存中,也写入预写日志 (WAL)。如果 Ingester(摄取器)突然终止,WAL 可以帮助恢复内存中的序列。TSDB在首次收到样本后,在每个 Ingester(摄取器)中延迟创建。当创建新的 TSDB 块时,内存中的样本会定期刷新到磁盘,并且 WAL 会被截断。默认情况下,这每两小时发生一次。每个新创建的块都会上传到长期存储(S3,OSS,Cloud Storage),并保留在 Ingester(摄取器)中,直至过期。
- Compactor(压缩器)将来自多个 Ingester(摄取器)的块合并到一个块中,并删除重复的样本来提高查询性能并减少长期存储使用量。
数据读取流程
- Grafana用户通过Query-frontend组件发起查询的请求,Query-frontend(查询前端)将较长时间范围的查询拆分为多个较小的查询。
- Query-frontend(查询前端)检查结果缓存。如果查询结果已缓存,则 Query-frontend(查询前端)返回缓存的结果。
- 无法从结果缓存回答的查询将放入 Query-frontend(查询前端)内的内存队列中。
- Querier(查询器)充当 worker(工作器),从队列中拉取查询。 Querier(查询器)连接到 Store-gateway(存储网关)和 Ingester(摄取器),以获取执行查询所需的所有数据。
- Querier(查询器)执行查询后,会将结果返回给 Query-frontend(查询前端)进行聚合。然后,Query-frontend(查询前端)将聚合的结果返回给客户端。
告警规则 (可选)
- Ruler 是一个可选组件,用于评估记录和告警规则中定义的 PromQL 表达式。每个租户都有一组记录和告警规则,并且可以将这些规则分组到命名空间中。
- Ruler 将规则评估委派给 query-frontend。启用后,Ruler 利用 query-frontend 采用的所有查询加速技术,例如 查询分片。要启用远程操作模式。
- Ruler 会将任何 FIRING (firing) 告警通知 Alertmanager。