在kubernetes中pod如何分配到节点中,都是由kube-scheduler组件来完成的,它通过不同的策略定义和规则来分配pod应该如何部署到期望的节点上。
kube-scheduler调度的原理
kube-scheduler会先在当前集群的所有节点里面通过调度算法(Predicate)选出所有适合运行被调度pod的节点。在所有的合适节点上再根据调度算法(Priority)挑选出最符合条件的节点来部署这个pod。
kube-scheduler实际上是通过2个循环来实现pod的调度工作的,下面是示意图:
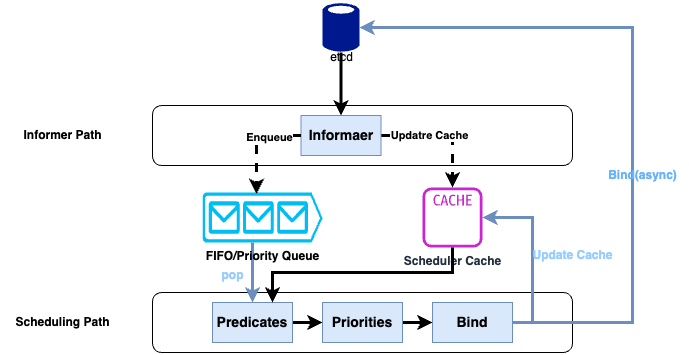
Informer Path
这个控制循环会启动各种informer来监听(Watch)Etcd中的Pod,Node,Service等与调度相关的API对象的变化。比如一个新的pod被创建后,调度器就会通过pod informer的handler将这个新创建的pod添加进调度队列(默认情况下,kubernetes的调度队列是Prioity Queue(优先级队列)。 从上图可以看到调度器还会对调度器缓存(Schedule Cache)进行更新。使用缓存的目的就是为了提高断言(Predicate)和优先级(Priority)调度算法的执行效率。
Scheduling Path
这个控制循环是调度器负责pod调度的主循环,它循环的从调度队列里面拿出一个pod,然后调用断言(Predicate)算法对所有节点进行“过滤”从而获取可以运行这个pod的宿主机列表。节点信息则是从Scheduler Cache里面获取的。然后调度器会再调用优先级(Priority)算法为所有符合条件的节点打分,分数的范围是从0—10,得分最高的节点将作为此次调度的结果。
调度器此时会把节点和pod进行绑定(Bind),其实就是修改pod对象的nodeName的值,但是为了不在关键调度路径里远程访问APIServer,kubernetes的默认调度器在绑定阶段只会更新Scheduler Cache里的pod和node的信息。这种更新api对象缓存的方式在kubernetes中叫assume.在assume后,调度器就会创建一个goroutine来异步地向APIServer发起更新pod的请求,来完成真正的绑定(Bind)操作。就算这次同步失败了,等Scheduler Cache同步之后一切就会恢复正常。
当这个新的pod完成了调度需要在某个节点上运行起来之前,此节点上的kubelet还会对此pod进行二次验证来确定此pod是否能运行在改节点上,这步操作叫做Admit操作。
调度器的扩展
扩展的图片就引用官网的了
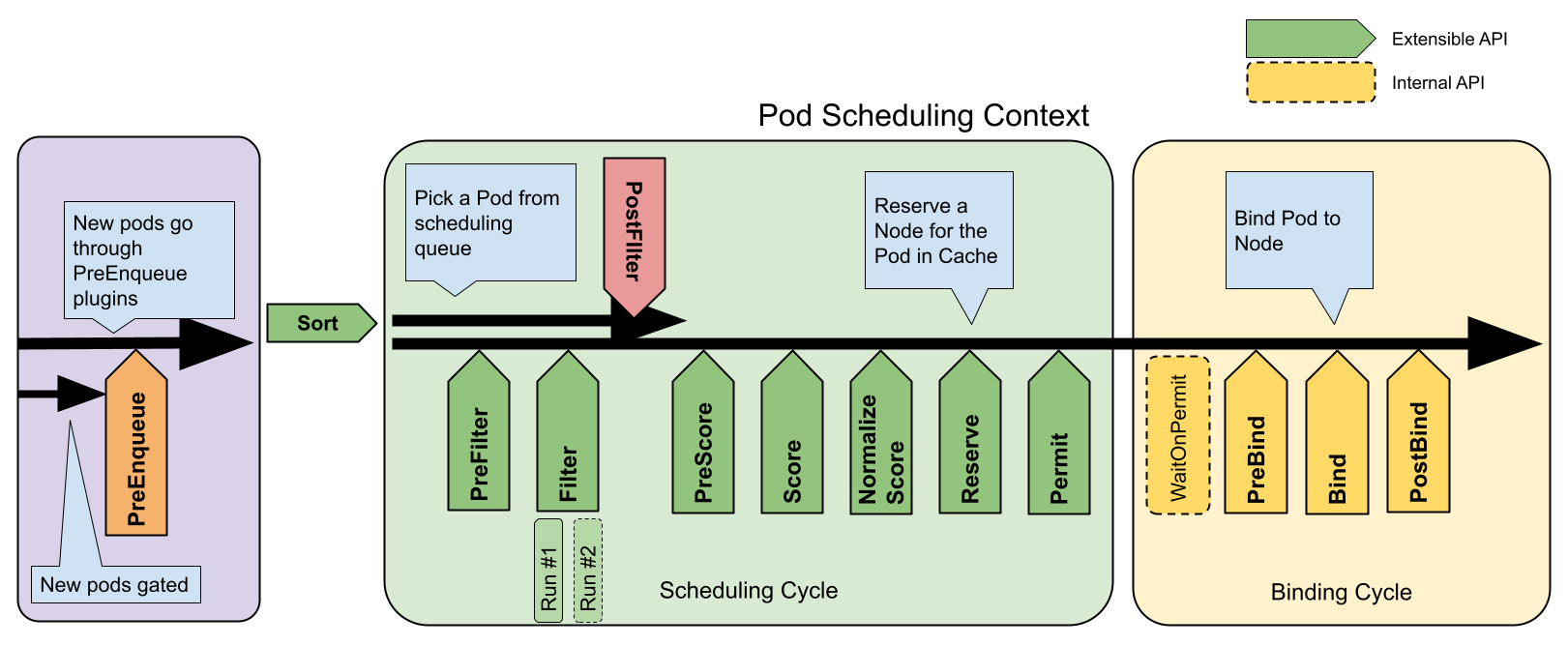
在调度器生命周期的各个关键点,为用户暴露出可以进行扩展和实现的接口,从而实现用户自定义调度器的能力。 不过这些可插拔的逻辑都是基于Go语言的插件机制,所以你必须在编译的时候就要把需要的插件加进去一起编译。